近些年信息化数字化的浪潮下,企业的IT资产和线上业务的规模迅速增长,而为了维护其稳定性和服务质量,所需耗费的成本、精力也在逐年攀升。
在此背景下,告警治理根本目标就是能够实现快速响应和解决故障,减少故障发生率和业务影响范围,而这一环节中,不可避免地会遇到诸如以下的典型问题:
- 告警散落不标准:在相互隔离的多个监控系统中,散落着没有统一的格式内容规范的各类告警,缺少集中式的管理工具,且告警信息不全面,可读性低。
- 告警噪音多:各监控系统,人工设置固定阈值的标准不一、同一故障可能引发不同系统告警,导致大量的误报、漏报、重复告警,也引起定位问题困难,或责任人明确。
- 缺乏工具联动:告警处理人工干预过多,自动处理少,告警流转效率低,过程缺少追踪,处理经验沉淀难。
- 缺乏全局视图:无法直观了解应用系统&对象模型的告警整体情况和关联影响范围。
……
“工欲善其事,必先利其器。”
企业要实现运转良好的告警管理流程,就需要利用好告警管理工具,从而能够更快更低成本的达成目标。接下来我们就以betway必威鲸眼告警中心为例,从告警管理流程出发进行“顺藤摸瓜”,对过程中的“告警集中汇聚”、“告警信息丰富”、“告警收敛降噪”三个重要典型场景进行拆解分析,分享企业实现良好告警管理流程的经验。
01. 告警集中汇聚:让信息不再是一盘散沙
通常情况下很难有大而全的监控系统能够同时囊括服务器、网络、数据库中间件、存储、应用系统、日志、机房动环等多种IT资产/业务系统的监控诉求。因此,大部分企业都会建设多套监控系统以应对不同的业务需求。但这样的烟囱式架构,存在重复建设、数据难互通、维护成本高等问题。
解决问题的第一步,就是将这些分散在不同监控系统中的全量告警汇聚起来,经过流程流转,对外发送统一、明确、及时的告警信息,使得事件得到快速有效的处理。实现集中汇聚告警,需要解决如下要点:
- 多种灵活汇集方式,统一管理告警
betway必威鲸眼告警中心,支持常规固定格式的REST API推送,还支持通过接口调用获取、数据库拉取、kafka对接、SNMP Trap推送、socket连接等多种方式,能有效满足各类对接需求,使分散在各个监控系统中的告警能够有效汇聚起来,统一管理。
- 低门槛在线拓展能力,保障持续发展
企业在业务发展的同时,也伴随着新的系统的引入和建设,告警系统需要具备拓展性,以应对未来的业务需求。
betway必威鲸眼告警中心,在持续积累对常见监控系统开箱即用对接能力的同时,开放了以python脚本形式的开发独立插件的能力,用户可以在不影响线上系统稳定的情况下,便捷的对接更多的第三方告警源(即监控系统),企业运维人员只需要简单的脚本开发基础,即可具备持续拓展能力,逐步转型运维开发。
- 个性化定义,清晰展示不同告警
通常情况下,来自不同监控系统的告警信息并不完全一致,在告警信息存在较大差异时,清晰明了的告警内容分级分类展示,能够有效提高运维人员处理告警信息的效率。
betway必威鲸眼告警中心,支持用户通过插件文件定义第三方系统的字段与告警中心标准字段的映射、清洗规则,并且支持针对每个告警源设定数量不限的拓展字段,以应对个性化需求。
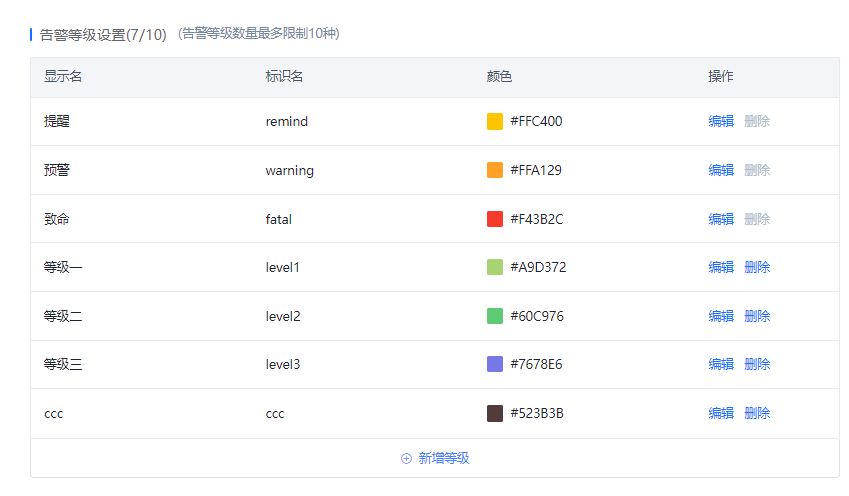
其中针对告警等级,除了常规的等级映射之外,用户还可自定义拓展更多等级,设定每个等级需要的显示名,标识颜色等。
- 快速同步告警状态,避免重复操作
告警系统除了接入触发的新告警,也需要支持在监控系统检测到告警恢复,或监控系统自行关闭告警、由于监控策略关闭而关闭告警后,对此类终态告警进行同步对接,以免在多个系统发生重复操作。
betway必威鲸眼告警中心,支持在恢复或关闭的告警接入时,按照相同的告警事件ID,找到触发的有效告警,自动完成告警状态的变更,还可以按需补充告警恢复/关闭时间、关闭原因等信息。对关闭和恢复做区分,能进一步明确状态,避免用户误解。
- 确定告警事件唯一性,精准定位来源
对于告警系统来说,仅对每一条入库告警赋予唯一的告警ID,是不足以做好去重和对应恢复/关闭的,需要另外的特性ID来共同确定告警事件的唯一性。如果交由告警源来提供事件的特性ID字段,实际落地会遇到很多系统无法提供的问题;而如果通过告警事件的属性字段如“告警对象、告警内容”自动判断告警的唯一性,适用性广,落地方便,但不够灵活。
betway必威鲸眼告警中心,采用“预定义+可扩展”的方式,默认规则是通过“告警源、告警对象、告警等级、告警指标”组合生成唯一的告警事件ID,同时也支持用户自行配置唯一性判断的字段,确保告警事件唯一性,精准定位告警来源并进行有效处理。
02. 告警信息丰富:探本求源精准定位问题
为什么需要对告警信息进行丰富呢?
在汇聚不同监控系统的告警过程中,运维人员通常会发现不同监控系统、不同类型的告警信息差别很大。有些监控系统的告警,信息充足且规范,除了完整的告警指标、等级以及告警对象的实例名等,还附带有告警主体所在业务拓扑信息;而另外一些系统的告警信息比较简陋,只有诸如:一个ip地址、磁盘空间使用率过高等信息。即使通过告警源插件文件做了对告警标准字段的清洗、映射,仍无法有效解决信息偏差较大的问题。如下所示:


而告警丰富功能,可以通过界面化配置,通过和CMDB(配置管理数据库)的关联,高效消费用户维护在CMDB中的实例配置信息,关联关系等;还可以对告警信息完成轻量化的二次清洗,免除频繁修改插件文件的工作量,便捷地实现告警事件内容、格式的统一。告警丰富在提升告警可读性的同时,能够提供告警治理的抓手,便于完成后续更灵活的告警筛选和更简便的策略配置,有效提升分析和处理故障的效率。以betway必威鲸眼告警中心为例,以下是两种告警丰富功能的落地实践分享:
1. CMDB丰富
上文我们提到,当第三方监控系统的告警信息比较简陋,并不包含用户分析和处理告警事件所需的全部信息时,用户还需要根据告警中的IP地址等信息,在CMDB中手动查询需要的内容,两相对照才可完成进一步的处理。
通过CMDB丰富,可以直接将告警对应的主体各项配置信息(实例的属性信息)自动添加到告警中,让用户一目了然的看到所有需要的信息。
下图为典型示例,当主机发生告警时,将主机的各项配置信息显示在告警内。

当然,配置告警字段和CMDB实例属性信息的映射规则,生效的前提是告警可以找到唯一的实例。对于没有和CMDB关联的第三方监控系统,可以通过配置CMDB关联规则来实现:根据告警字段和CMDB则能够根据告警内容中正则提取的IP地址和CMDB中的内网IP属性值进行比对,以准确找到唯一对应的实例,从而实现后续的字段信息丰富。
实际效果如下所示:


2. 常规丰富
通过字符替换、字符提取、字段调整等方式,以页面配置的方式,对告警信息进行标准化清洗,同时运维人员可以自定义上述方案的生效规则和应用范围,从而快速实现对需要处理的部分告警信息的丰富。
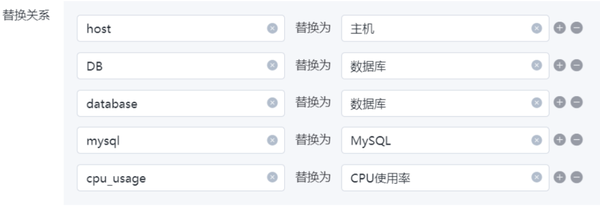
1)字符替换
当相同事务在不同系统间名称不同时,如有些系统是中文:主机、数据库,有些是英文:host、DB、database;还有些是名称不规范,如mysql、MYSQL等。可以通过字符替换功能,对每个告警源的告警配置翻译替换规则,便于运维人员理解。
2)字符提取
有些系统的告警将指标当前的具体值写入一个独立的拓展字段内,而另一些系统的告警,只能从告警内容字段中找到指标具体值,如zabbix的告警,告警内容的尾部the value is 之后就是监控指标的当前值。
通过字符提取功能,灵活运用正则表达式,将指标的当前值从告警内容中拆分出来,进一步实现指标规范,让所有系统的告警,都将指标具体值单独显示为一个字段。

3)字段调整
类似的,对于一些监控系统定义了很多拓展字段,而用户使用过程中,想要将这些字段合并为一个,更便于去查看,也可以通过字段的调整功能实现。
例如某系统的告警,将主机所在位置,分城市、机房、机柜三个字段显示,通过字段调整,将三个字段合并为机器位置这一个字段。

4)自定义应用范围
大多数情况下,我们需要的只是上述提到的方案对某一部分的告警生效。那么可以通过配置策略匹配规则,制定方案应用范围:按告警字段进行筛选,如“告警内容”包含某个信息,或者“告警对象”匹配某个正则表达式等,让符合条件的告警执行设定的方案。
03. 告警收敛降噪:去芜存菁,剔除“无效告警”
实现告警集中和信息丰富之后,自然而然就遇到了另一个亟待解决的问题——告警噪音过多。一线团队可能每天都会收到几千封告警通知,但精力范围内可处理的数量却远远不及。疲于应对的同时,无法从汪洋大海一般的告警中甄别出真正重要的内容。
部分团队无奈之下,可能会采取一种简单粗暴的方式,即通过告警等级来区分,优先处理最高等级的告警(实际上也只能够勉强处理最高等级告警)。
然而这种方式实际上存在着极大的隐患:在各个监控工具上,对于不同的监控对象、监控指标设置的阈值标准,不一定具备实际的业务含义,必然存在大量的误报、漏报。
另外经常忽略低等级告警信息,就不能及时发现故障前兆,而当致命故障发生时,处理难度会更大,也对业务服务和终端用户造成更大范围的影响。
只有通过合理高效的告警降噪能力,才能够帮助运维人员在有限的时间范围内快速、智能地筛选、定位出真正需要关注或人工处理的告警,以点带面,大幅降低故障影响范围,更好的感知到当前需要处理的告警全貌,维护业务的稳定。
而完成告警降噪,首先需要定义哪些属于理应被压缩的“无效告警”,然后针对各类告警制定相对应的解决方案,最终快速实现高效的告警降噪。
1. 常见“无效告警”:
- 维护期告警:在应用发布/迁移/切换、环境维护、例行重启、灾备演练等变更维护期间,所产生大量无需关注的告警。
- 重复告警:监控系统在故障未解决的情况下持续检测,持续发送的告警。
- 相同维度告警:多个监控系统监控覆盖面有重叠,对同一个IT设备的相同问题,来自不同监控系统,多条具备相同维度属性的告警,如同一个对象相同指标的告警、或者具备相同的业务、集群、模块、关联信息等属性的不同对象的告警。
- 相同负责人告警:隶属于同一个人负责的,短时间内集中爆发的告警。
- 抖动类告警:CPU使用率、网卡流量等指标偶发高于阈值的告警。
- 快速恢复告警:产生后较短时间(如2分钟内)内自动恢复的告警。
- 依赖相关告警:依赖关系引发的告警,如数据库运行于主机,或设备通过交换机联通网络等,由于被依赖设备产生故障而导致由依赖关系的的告警。
2. 对应的制定告警降噪的方案:
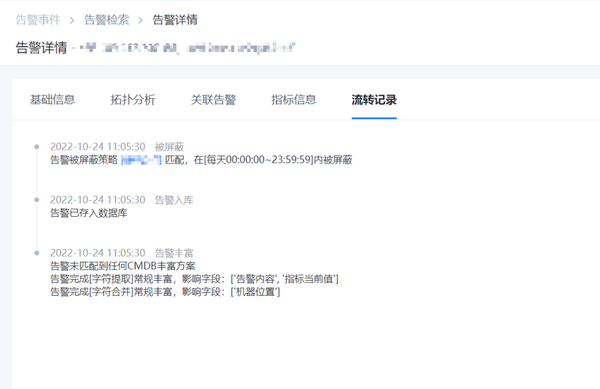
1)时间屏蔽
由于系统变更、跑批等维护期间,很少会采取同时停止监控的方式,所以因系统、设备的异常态而必然引发的告警,可以通过告警屏蔽,实现对指定时间窗口内可预知的无效告警进行收敛——不会分派通知,也不出现在需要处理的告警列表中。
2)告警去重
betway必威鲸眼告警中心采取自动去重策略。当一条告警还处于处理中未结束的状态(下文中称此类告警为“活动告警”),后续接入的重复告警,会被自动收敛掉。此处的重复告警的定义,取决于在接入告警环节告警事件的唯一性方案。相同告警事件ID的告警,被视为重复告警。
收敛同时累加活动告警的“告警计数”,并将被收敛的告警和对应的活动告警进行关联。

3)关联聚合
将某个时间窗口内,指定的一个或多个告警字段完全相同的多条告警聚合,让这些相同维度或者相同负责人的告警,只分派通知一次,减少对运维人员的打扰,又可以便捷的查看所有聚合的告警。
例如配置将主机产生的告警,在设定的10分钟时间窗口内,有着相同的“告警指标、CMDB业务、主要维护人”的多条告警收敛为一条。
这也可以视为一种更灵活的去重策略,能有效解决内置自动去重策略所未涉及的一些场景,如:来自同一个监控系统的不同类型/不同负责人告警,告警事件唯一性方案有区别,需要灵活的设定;用户希望超过一定时间段后,再此生成一条新的活动告警,而非全部抑制等。
4)告警防抖
某些监控系统不具备防抖检测机制,经常出现一些指标值突升突降,引发很多迅速恢复的告警,这使得运维人员收到大量告警后来不及查看又恢复了。
在实际的业务场景中,虽然这些指标设定的阈值是合理的,超过阈值需要告警,但用户希望仅当指标值连续几个检测周期,持续高于阈值再发出告警通知。
那么对于这些抖动类指标(如CPU使用率、网卡流量、内存使用率、磁盘IO等)产生的告警,可以设定一些防抖的规则。如5分钟内产生3次告警,第3次才会成为有效告警进行分派通知,未达标的偶发告警即被抑制。
5)依赖告警收敛
对于有依赖关系影响而导致的关联告警事件,如组件安装/运行于主机、各设备通过交换机连通网络、主机磁盘挂载了存储提供的存储盘、虚拟机运行于宿主机或宿主机集群上等,通过配置依赖关联规则,按照告警之间的依赖关系,将依赖告警进行收敛。
根据目前的落地实践,通过以上五种降噪方案的配置,企业一般能够有效收敛60%~80%的告警量。
6)智能化降噪未来展望:
当然,在后续产品能力建设过程中,还需要考虑如何进一步提升降噪效果,减轻人工配置的工作量同时增强告警智能化降噪的能力。对此我们也可以展望未来的一些建设发展方向:
7)智能聚类告警
通过AI人工智能技术,如NLP算法(自然语言处理Natural Language Processing)、DBSCAN聚类算法,对告警信息进行文本分类聚类、模式发现,从海量告警中自动化地去学习告警之间的关联或相似关系,然后对相似、相关的告警进行收敛。
通过有监督的机器学习能力,结合人工标记误告或错误收敛的告警,在最小化用户配置成本的同时,逐步提高智能聚类告警的准确性和可靠性。
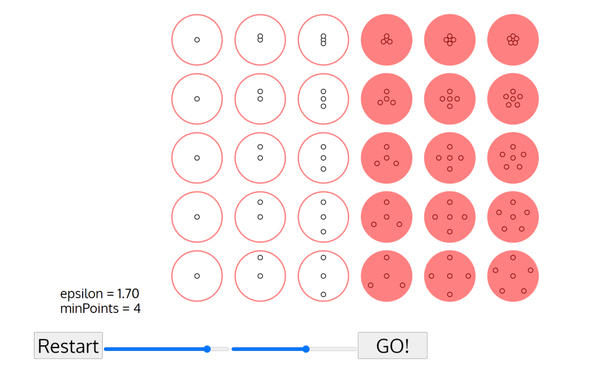
对DBSCAN聚类效果演示感兴趣的读者可以在相关网站深入探索,此处不作进一步展示。
2. 抑制快速恢复告警
对于一些会在产生告警后几分钟又迅速恢复的告警,不需要立刻分派通知的,可以在缓存一段时间后(可以设置最大延迟时间如5分钟,从而保证告警时效性),这段时间内未恢复的告警,再作为有效告警,通知相关人员处理。
1)告警事件合并
通过一些用户自定义的合并规则,将一个时间窗口内,多条有关联的告警合并到一起,衍生一条新的告警事件,可以生成一些组合的告警信息,在告警通知信息中,体现合并告警的原因和影响范围,让运维人员更有针对性去排查故障。
2)拓扑关系收敛
通过调用CMDB拓扑(组件实例间的关联关系)、APM应用拓扑(服务调用依赖关系,如前端应用调用后台服务、进程等),根据完善的拓扑关系,自动生成依赖收敛规则,极大减轻手工维护依赖关系的工作量。
相关文章推荐
DevOps系列:CICD流程建设之持续测试实践指南

 2024-10-16
2024-10-16
查看详细


betway必威蓝鲸配置管理中心重磅发布,数据运维全面升级!
2024-10-16
查看详细
betway必威蓝鲸 WeOps V4.15上新 | 增强阿里云资管和监控能力
2024-09-11
查看详细
【新品发布】betway必威蓝鲸WeOps运维平台一体机全新发布:高性价比、强大稳定、即插即用的企业级IT运维设备
2024-09-11
查看详细
一文掌握DevOps落地的终极实践,8大关键路径揭秘!
2024-09-10
查看详细
DevOps 组织的建设密码:人才胜任力模型全解析
2024-09-10
查看详细







